tl;dr
Computed variables have been available in jamovi for a while now. Although great for a lot of operations (e.g., calculating sum scores, generating data, etc.), they can be a bit tedious to use when you want to recode or transform multiple variables (e.g., when reverse-scoring multiple responses in a survey data set). Today we’re introducing ‘Transformed variables’, allowing you to easily recode existing variables and apply transforms across many variables at once.
Creating transformed variables
When transforming or recoding variables in jamovi, a second ‘transformed variable’ is created for the original ‘source variable’. This way, you will always have access to the original, untransformed data if need be. To transform a variable, first select the column(s) you would like to transform. You can select a block of columns by clicking on the first column header in the block and then clicking on the last column header in the block while holding the shift key. Alternatively, you can select/deselect individual columns by clicking on the column headers while holding down the ctrl/cmd key. Once selected, you can either select ‘Transform’ from the data tab, or right click and choose ‘Transform’ from the menu.
- Right-click on one of the selected variables, and click
Transform...: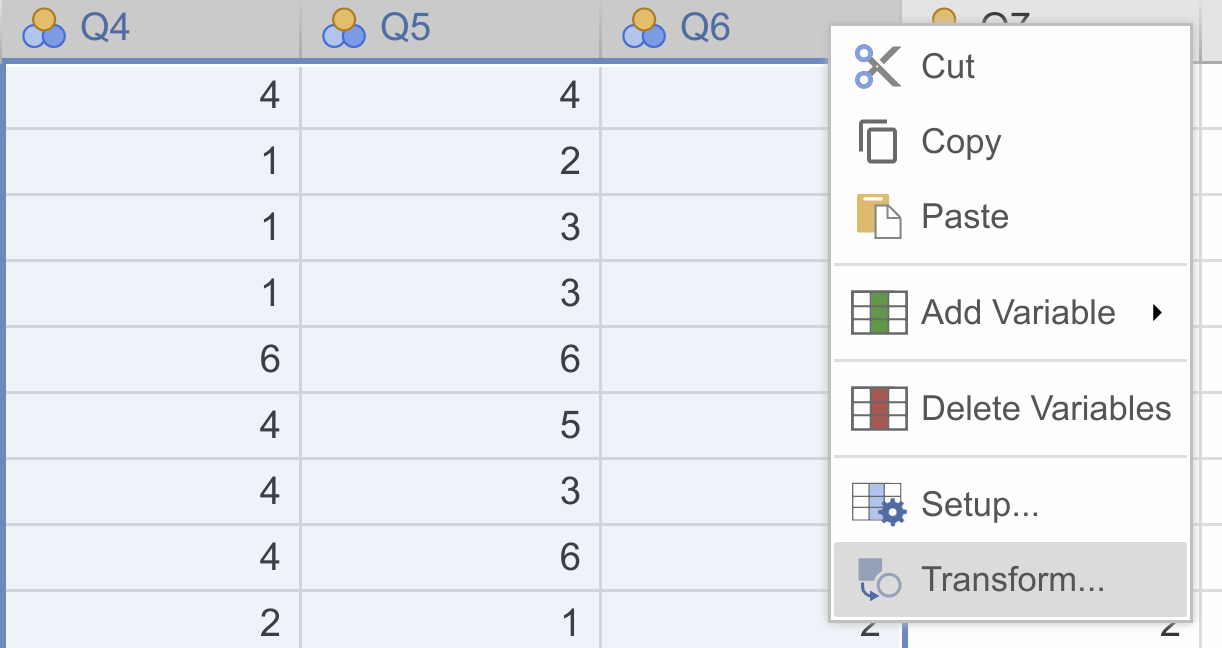
- Go to the
datatab, and clickTransform: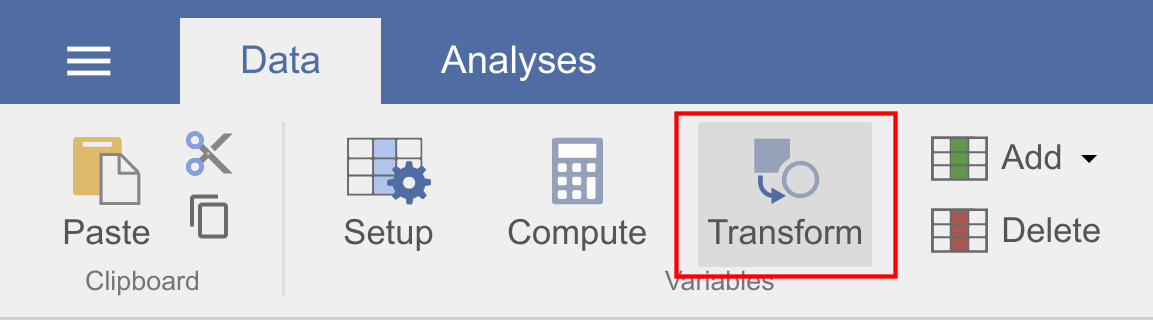
This constructs a second ‘transformed variable’ for each column that was selected. In the following example, we only had a single variable selected, so we’re only setting up the transform for one variable (called score - log), but there’s no reason we can’t do more in one go.
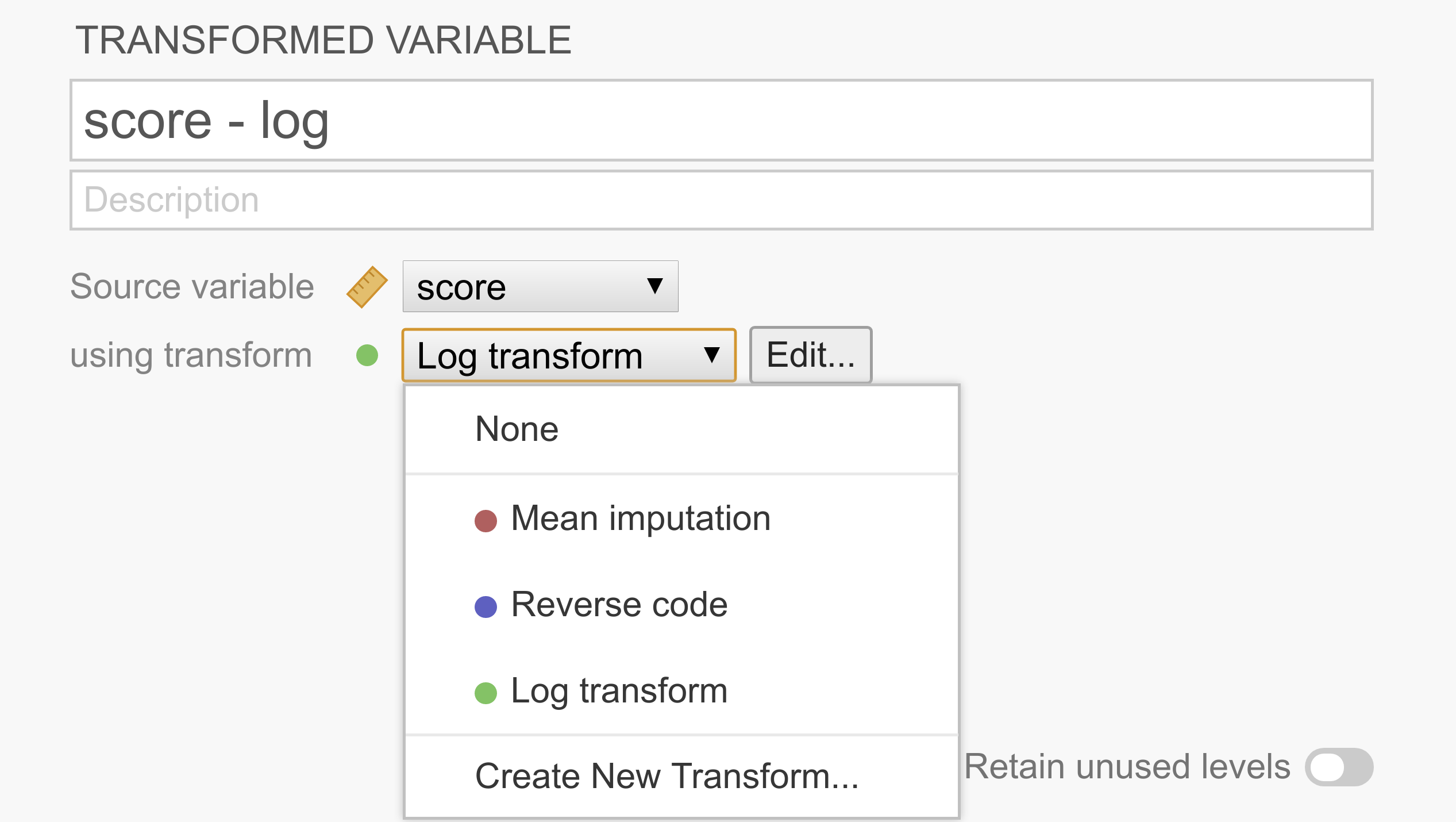
As can be seen in the figure above, each transformed variable has a ‘source variable’, representing the original untransformed variable, and a transform, representing rules to transform the source variable into the transformed variable. After a transform has been created, it’s available from the list and can be shared easily across multiple transformed variables.
If you don’t yet have the appropriate transform defined, you can select Create new transform... from the list.
Create new transformation
After clicking Create new transform... the transform editor slides into view:
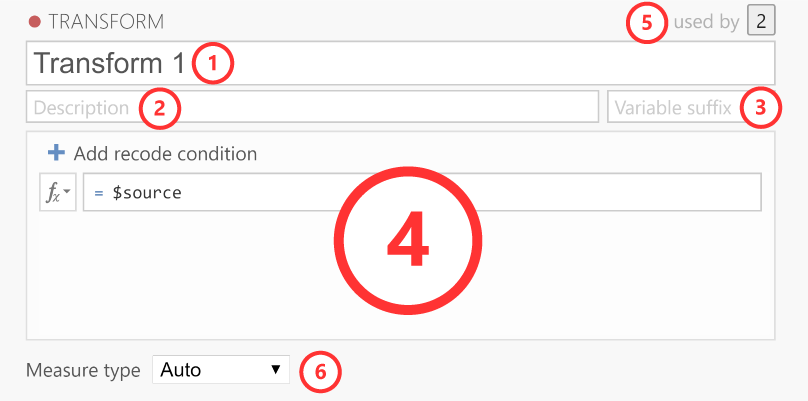
Let’s take a look at each of these elements.
1. Name
The name for the transformation.
2. Description
Space for you to provide a description of the transformation so you (and others) know what it does.
3. Variable suffix
Optional. Here, you can define the default name formatting for the transformed variable. By default, the variable suffix will be appended to the source variable name with a dash (-) in between. However, you can override this behavior by using an ellipsis (...), which will be replaced by the variable name. For instance, if you transform a variable called Q1, you could use variable suffixes to apply the following naming schemes:
log→Q1 - log..._log→Q1_loglog(...)→log(Q1)
If left empty, the transformation name is used as the variable suffix.
4. Transformation
This section contains the rules and formulas for the transformation. You can use all the same functions that are available in computed variables, and to refer to the values in the source column (so you can transform them), you can use the special $source keyword. If you want to recode a variable into multiple groups, it’s easiest to use multiple conditions. To add additional conditions (i.e., if-statements), you click on the ‘Add recode condition’ button:
5. Used by
Indicates how many variables are using this particular transformation. If you click on the number it will list these variables.
6. Measure type
By default the measure type is set to Auto, which will infer the measure type automatically from the transformation. However, if Auto doesn’t infer the measure type correctly, you can override it over here.
Example 1: Reverse scoring of items
Survey data often contains one or more items whose values need to be reversed before analyzing them. For example, we might be measuring extraversion with the questions “I like to go to parties”, “I love being around people”, and “I prefer to keep to myself”. Clearly a person responding 6 (strongly agree) to this last question shouldn’t be considered an extravert, and so 6 should be treated as 1, 5 as 2, 1 as 6, etc. To reverse score these items, we can just use the following simple transform:
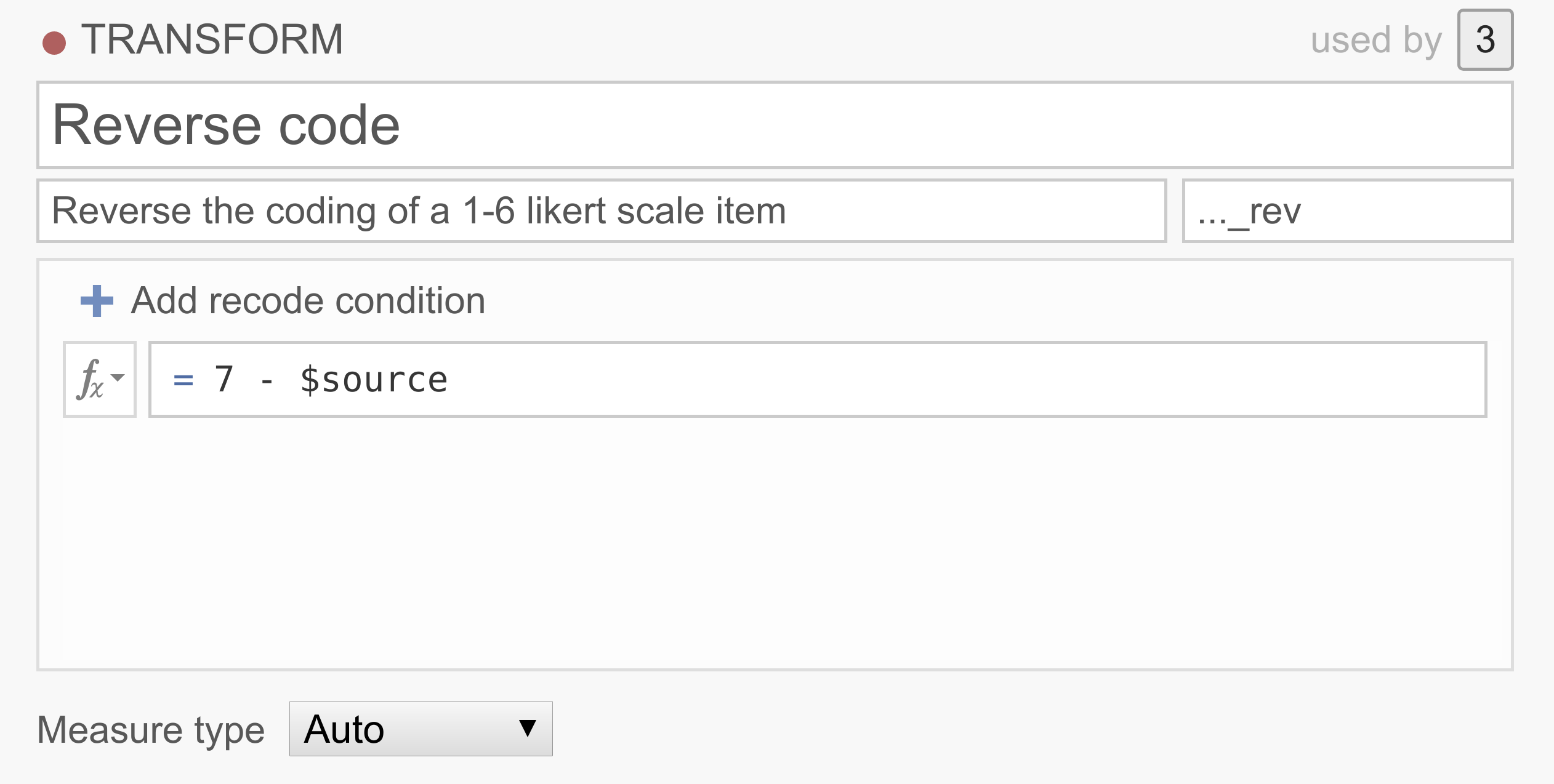
You can explore this transform by downloading and opening the file transform_ex1.omv in jamovi.
Example 2: Recoding continuous variables into categories
In a lot of data sets people want to recode their continuous scores into categories. For example, we may want to classify people, based on their 0-100% test scores into one of three groups, Pass, Resit and Fail.
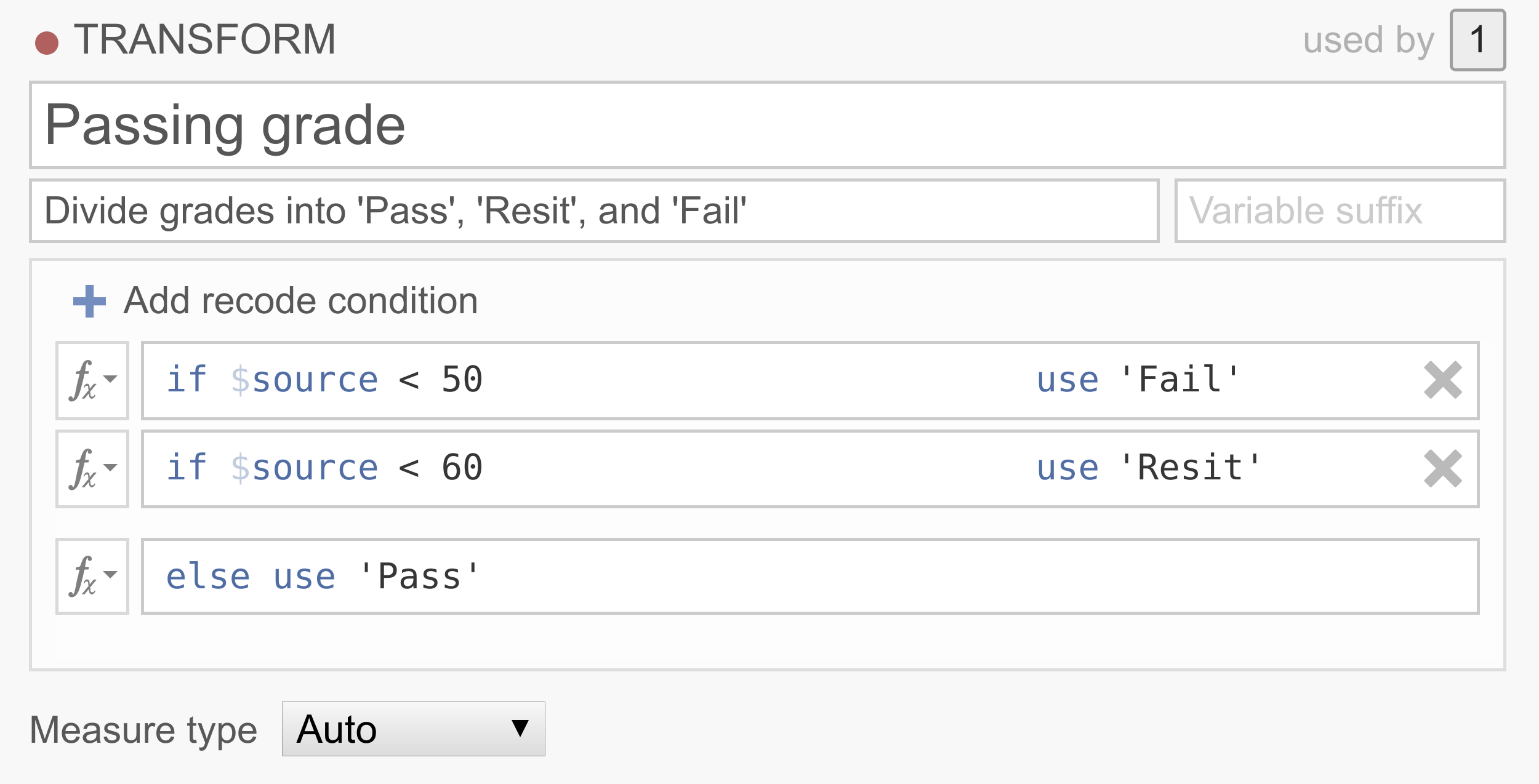
Note that the conditions are executed in order, and that only the first rule that matches the case is applied to that case. So this transformation basically says that if the source variable has a value below 50, the value will be Fail, if the source variable has a value between 50 and 60, the value will be Resit, and if the source variable has a value above 60, the value will be Pass. If you’d like an example data set to play around with, you can use transform_ex2.omv.
Example 3: Replacing missing values
Now, let’s say your data set has a lot of missing values and removing the participants with missing values will end up in a severe loss of participants. There are a number of ways to deal with missing data, of which imputation is quite common. One pretty straightforward imputation method replaces the missing values with the variable mean (i.e., mean substitution). Although there are a bunch of problems associated with mean substitution and you should probably never do it, it does make for a neat demonstration :P
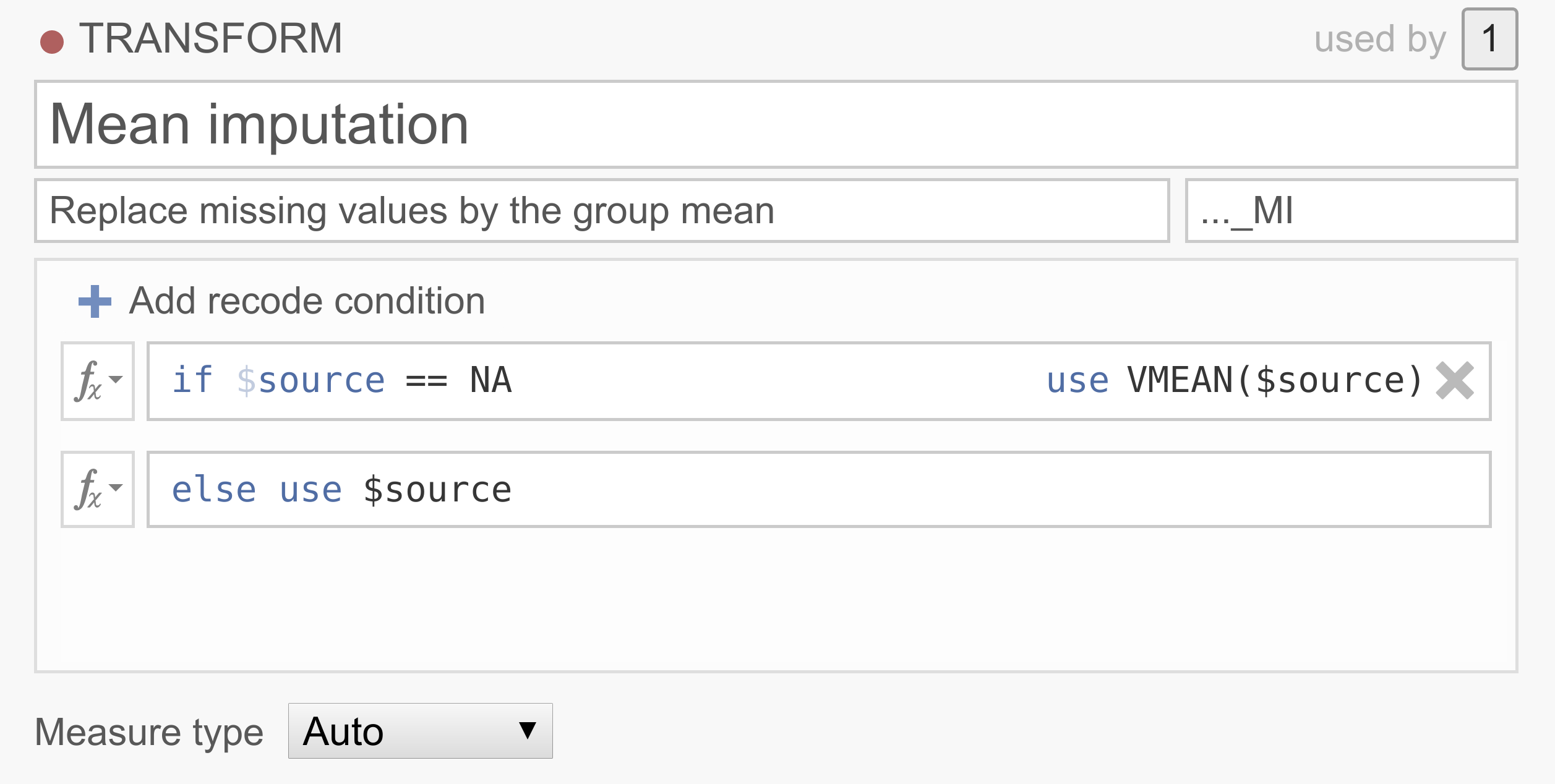
Note that jamovi has borrowed NA from R to denote missing values. Don’t have a good data set handy? You can try it out yourself with the transform_ex3.omv data set.
Conclusion
Transformed variables are a great tool for transforming and recoding data, and solve a lot of different data manipulation problems. For us, the jamovi developers, transformed variables represent a really significant milestone. jamovi is now able to service the majority of social scientists data-wrangling needs. jamovi has become far more than an educational tool, and can increasingly hold it’s own alongside the giants in the field (SPSS et al.).
Transformed variables are available from jamovi 0.9.5 upwards. We hope you will enjoy it :)
Comments